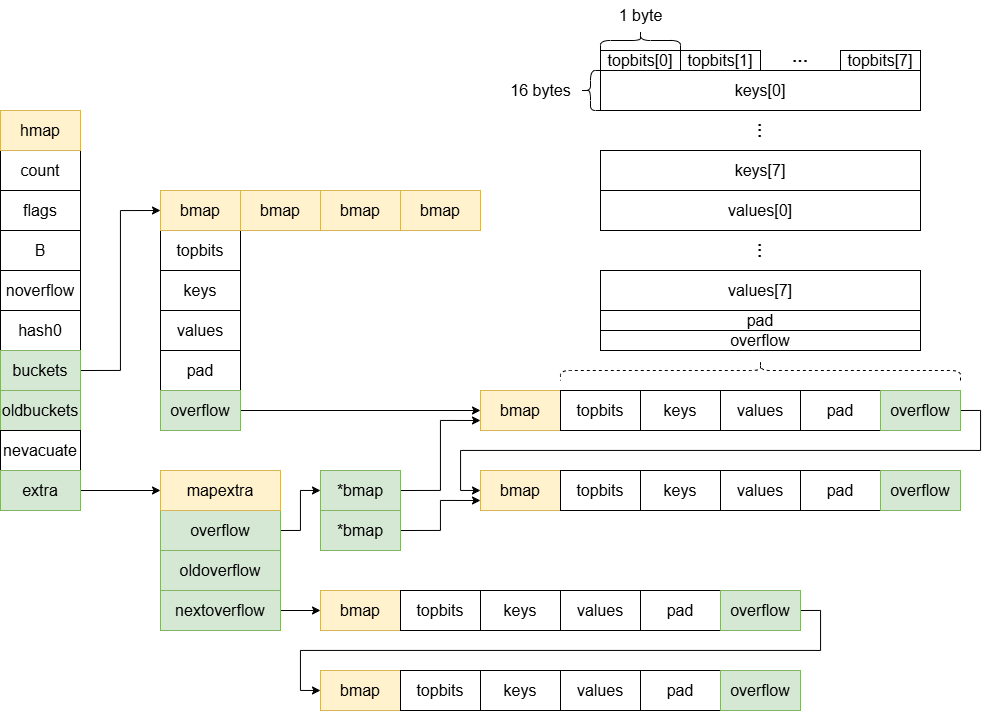
type hmap struct {
count int // 当前 map 中的元素数量
flags uint8
B uint8 // B = log_2(len(buckets))
noverflow uint16 // 溢出桶的近似数量
hash0 uint32 // hash 种子
buckets unsafe.Pointer // 如果 map 中的元素数量为 0,为空
oldbuckets unsafe.Pointer // 仅扩容时非空
nevacuate uintptr // 迁移进度计数器,小于该值的桶已被迁移
extra *mapextra
}
type mapextra struct {
overflow *[]*bmap // 指向一个保存所有溢出桶地址的数组
oldoverflow *[]*bmap
nextOverflow *bmap // 指向一个预分配的空闲溢出桶
}
/*
type bmap struct {
tophash [bucketCnt]uint8
}
*/
type bmap struct {
topbits [8]uint8 // 根据 key 计算出哈希值的高 8 位,加速 key 查找;状态值
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}topbits 状态值
所有根据 key 计算出哈希值的高 8 位 topbits 必须大于等于 minTopHash,如果 topbits < 5,topbits += minTopHash
emptyRest = 0
emptyOne = 1
evacuatedX = 2
evacuatedY = 3
evacuatedEmpty = 4
minTopHash = 5- emptyRest (topbits == 0):
- 该 topbits 对应的 key 和 value 为空
- 后面所有的 key 和 value 都为空(后面没有元素)
- 初始化时,桶中所有 topbits 会被置为 emptyRest
- emptyOne (topbits == 1):
- 该 topbits 对应的 key 和 value 为空
- 后面还有元素
- evacuatedX (topbits == 2) & evacuatedY (topbits == 3):这两个状态与扩容有关,记录元素被迁移到了新桶的部位 X 或 Y
- 如果是等量扩容,旧桶元素必然被迁移到部位 X
- 如果是双倍扩容,旧桶元素可能被迁移到部位 X,也可能被迁移到部位 Y(当被迁移到部位 X 时,旧桶的 topbits 被置为 evacuatedX;当被迁移到部位 Y 时,被置为 evacuatedY)
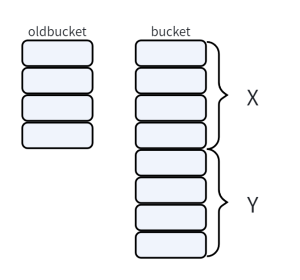
- evacuatedEmpty (topbits == 4):已被迁移的空槽位
扩容
扩容策略
- 装载因子超过 6.5(装载因子 = count / 2^B):双倍扩容
- 溢出桶的数量过多(超过 2^B 时):等量扩容(使 key 排列得更紧密)
- 插入大量元素,导致创建了很多溢出桶,但装载因子未达到双倍扩容的阈值;删除大量元素,再插入大量元素,又导致创建了很多溢出桶,但装载因子仍未达到双倍扩容的阈值。此时溢出桶数量太多,key 分散在大量溢出桶中
渐进式迁移
- 若 map 中元素数量太多,一次性将所有元素从旧桶迁移到新桶,开销太大
- 写时复制 (仅在插入、修改或删除时迁移),每次至多迁移 2 个桶
hashGrow():分配新桶,并将旧桶挂在 oldbuckets 上growWork():判断当前旧桶是否已被迁移,来决定迁移与否;当 nevacuate 等于旧桶数量时,迁移完成,释放旧桶及其溢出桶
访问
- 判断当前 map 是否处于扩容状态:
- 若处于扩容状态,根据 hash 值的低 B 位在 oldbuckets 中命中桶
- 桶中第一个槽位 1 < topbits < 5:当前桶已被迁移,根据 hash 值的低 B 位在 buckets 中命中桶,在该桶中查找 key
- 否则,在当前桶中查找 key
- 否则,根据 hash 值的低 B 位在 buckets 中命中桶,在该桶中查找 key
- 若处于扩容状态,根据 hash 值的低 B 位在 oldbuckets 中命中桶
- 遍历桶内 8 个槽位,比较每个槽位的 topbits 是否和当前 key 的 topbits 相同
- 相同,比较 key 是否相同,相同则直接返回对应 value,不同则遍历下一个槽位
- 不相同
- 该槽位 topbits == emptyRest:后面没有元素了,未找到,返回 value 对应类型的零值
- 否则,遍历下一个槽位
- 遍历溢出桶
写入
- 判断当前 map 是否处于扩容状态,若处于扩容状态,根据 hash 值的低 B 位在 oldbuckets 中命中桶
- 迁移该桶,并额外迁移索引为 nevacuate 的桶,nevacuate += 1
- 根据 hash 值的低 B 位在 buckets 中命中桶
- 遍历桶及其溢出桶的每个槽位,比较每个槽位的 topbits 是否和当前 key 的 topbits 相同
- 相同,比较 key 是否相同,相同则修改对应的 value,不同则遍历下一个槽位
- 不相同
- 该槽位 topbits == emptyRest:后面没有元素了,map 中不存在相同的 key,立即插入 key 和 value
- 该槽位 topbits == emptyOne:标记为候选插入槽位,遍历下一个槽位
- 否则,表明该槽位有其他 key,遍历下一个槽位
- 如果有候选插入槽位,插入 key 和 value;否则,表明已无空槽位,申请一个新的溢出桶,在该溢出桶中插入
删除
- 判断当前 map 是否处于扩容状态,若处于扩容状态,根据 hash 值的低 B 位在 oldbuckets 中命中桶
- 迁移该桶,并额外迁移索引为 nevacuate 的桶,nevacuate += 1
- 根据 hash 值的低 B 位在 buckets 中命中桶
- 遍历桶及其溢出桶的每个槽位,比较每个槽位的 topbits 是否和当前 key 的 topbits 相同
- 相同,比较 key 是否相同,相同则删除该 key 以及对应的 value,不同则遍历下一个槽位
- 该槽位 topbits == emptyRest:后面没有元素了,目标 key 不在 map 中
- 否则,遍历下一个槽位
- 删除后,将当前槽位的 topbits 置为 emptyOne,若后面一个槽位 topbits == emptyRest,从当前槽位开始向前遍历,直至第一个 topbits 不为 emptyOne 的槽位,将每一个槽位的 topbits 置为 emptyRest
遍历
每次遍历结果的顺序都不同:每次开始遍历时,随机选择一个桶,并随机选择桶内一个槽位(之后遍历每个桶时都从该槽位开始)

